

On me demande souvent ce que je fais dans la vie et je n’arrive pas à répondre.
Non pas parce que mon travail est flou, mais parce qu’il repose sur des concepts que la plupart des gens ne maîtrisent pas.
La manière la moins technique que j’ai d’expliquer ce sur quoi je travaille est la suivante:
« je m’occupe de la mise en production ».
Certes, mais c’est quoi une « production » ? Ce n’est pas une notion compliquée mais c’est une notion qui repose sur pleins d’autres concepts qui rendent son explication assez ardue.
De plus, on ne répond pas vraiment à la question, de savoir ce que la mise en production inclut comme travail.
J’en ai aussi beaucoup parlé aux développeurs que je rencontre et je me suis aperçu que peu d’entre eux s’intéressent à mon domaine d’expertise. Ce n’est simplement pas leur métier.
Pour aller plus loin, je m’occupe de la production au sens large. Et cela inclut les domaines suivants:
- L’architecture de la solution
- Le passage en production (pipeline de développement, ou chaine de production)
- Le maintien en conditions opérationnel (MCO)
- La sécurité
- Faire face à l’imprévu, évaluer les risques (connu sous le nom «Disaster Recovery»)
Et chacun de ces domaines mériterait un développement plus approfondi pour en expliquer les tenants et aboutissants. Chacune de ses notions reposant elle-même sur d’autres notions plus techniques.
On va essayer de survoler chacun de ces points dans cet article.
L’architecture
Pour que cela reste accessible, je vais partir de la présentation d’un cas courant : une application contenant un backend et un frontend. Dans notre exemple, l’application servira à trouver des restaurants.
Pour ce faire, l’entreprise devra développer plusieurs éléments:
- Une base de données pour y stocker les adresses et les spécificités de chaque restaurants
- Un backend, le cœur de l’application qui permettra de faire des recherches, d’enregistrer de nouveaux restaurants, etc…
- Un frontend, la partie visible pour l’utilisateur final, souvent dans le navigateur web ou une application mobile.
L’architecture, c’est la partie du travail nous permettant de dessiner le schéma suivant :
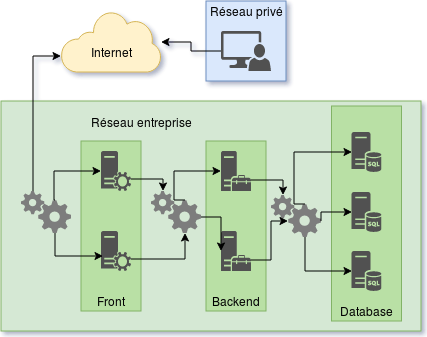
Comme on peut le voir sur le schéma ci-dessus, nous avons déjà besoin de 7 machines, puis de configurer les couches réseaux et de prévoir la redondance des services.
Cela reste un exemple très simple, il est assez fréquent de se retrouver face à une vingtaine de services répartis sur 30 à 40 machines.
Bien évidemment, toutes les entreprises ne mettent pas en place toute cette complexité dès la première ligne de code. Il faut faire des arbitrages et savoir ce qui est important pour que le service soit correctement rendu à l’utilisateur final.
Rien qu’en regardant ce schéma, j’ai d’ores et déjà une douzaine d’idées pour compléter l’architecture. Voilà donc la première partie de mon travail, à savoir réfléchir au système dans sa globalité pour voir les forces et les faiblesses de la solution. L’industrialisation (Le passage en production)
Sauf que voilà, une fois qu’on a notre schéma d’architecture, qu’on a 30 machines qui font tourner 20 services différents… Comment est-ce qu’on maintient tout ça ? Comment le fait-on évoluer ?
D’un point de vue technique, il suffirait de se connecter aux machines pour les configurer correctement, une par une. C’est une manière de faire que je croise très souvent dans les entreprises et malheureusement, ce n’est pas la bonne solution.
Se connecter aux machines pour les configurer à la main donne des configurations en flocons de neige (snowflakes en anglais). Puisque cela est fait à la main, même si on désire que toutes nos machines soient configurées de manière similaire, il y a toujours de petites différences entre chacune. Toutes les machines sont les mêmes, mais pas tout à fait #SameButDifferent
Les conséquences de cette pratique sont désastreuses : mettre en production est un enfer dans ces conditions. Chaque machine devant avoir un traitement différent, la mise en production peut donc prendre des jours et on est jamais certain du résultat.
L’industrialisation est donc la seconde partie de mon travail, et je dirais la plus importante. Il s’agit d’un processus finalement assez long, qui demande un investissement aussi bien en durée qu’en moyen. La plus-value n’étant pas immédiate ce n’est donc malheureusement pas toujours la priorité des entreprises.
En industrialisant, on automatise la création des images. Parce que oui, se connecter aux machines pour les mettre à jour comportent des risques, donc on crée plutôt des images.
Une image dans ce contexte n’a rien à voir avec les images que l’on trouve sur internet aux formats png ou jpeg. Il s’agit d’une « photo instantanée » d’une machine déjà configurée et prête à être employée. Ainsi, lorsque l’on déploie une machine grâce à notre image, elle est prête à délivrer le service que l’on attend d’elle sans qu’il y ai besoin d’opération manuelle à effectuer.
Ensuite, on automatise le remplacement des anciennes images par de nouvelles, afin d’assurer un passage en production en douceur, tout en réduisant le risque d’éventuelles interruptions.
Et cela va surtout permettre d’appuyer sur le bouton « mise en prod » l’esprit tranquille. Ceci grâce aux tests de chacunes de nos images. C’est ici que notre pipeline de production est important.
Le pipeline est la notion de chaîne de production, un peu à l’image des chaînes d’assemblage des automobiles. Notre chaîne commence avec le travail des développeurs qui proposeront de nouvelles fonctionnalités. Ensuite, cette fonctionnalité sera testée et approuvée par d’autres développeurs. Puis elle passera par l’étape de création de notre image, qui servira à créer un environnement de qualification. Cet environnement permettra aux clients de valider la fonctionnalité avant de valider la mise en production.
L’idée principale derrière l’industrialisation est donc de créer une chaîne de production qui permet à l’entreprise de:
- Livrer plus rapidement ses clients
- Fiabiliser les livraisons
- Banaliser la livraison (plus fréquent, plus rapide)
- Pouvoir valider ou invalider plus rapidement les nouvelles fonctionnalités
Même si, à première vue, la mise en place de cette usine logicielle peut paraître compliquée, la plus-value est indéniable. Je n’ai encore jamais vu d’entreprise regrettant d’avoir investi sur l’industrialisation de leur plate-forme.
À l’inverse, dans de nombreux cas, j’ai pu voir que l’entreprise n’est pas au courant qu’elle pourrait investir dans un projet d’industrialisation de ses mises en productions.
MCO: Maintien en conditions opérationnelles
Mettre en production c’est bien beau mais la vie ne s’arrête pas là. Malgré plusieurs années à m’occuper de différentes plateformes logiciel, je suis toujours stupéfait par la quantité de choses pouvant mal tourner, même en production.
Or une fois l’application en production, il faut maintenir celle-ci en état de marche. Une production à l’arrêt est une perte sèche pour l’entreprise. L’application ne peut rapporter de l’argent à l’entreprise que si elle est disponible pour ses utilisateurs finaux, ses clients. Il faut donc distinguer plusieurs états possibles:
- Les conditions opérationnelles, optimales, les clients n’ont aucune difficultée à se connecter.
- Les conditions dégradées, on constate certaines lenteurs, quelques déconnexions. Cet état est très frustrant pour l’utilisateur.
- L’arrêt, la production n’est plus accessible, plus aucun client ne peut se connecter.
On parle donc de Maintien en Conditions Opérationnelles (MCO). C’est un joli nom, mais incorrect selon moi. En réalité, on ne peut pas vraiment garantir de rester dans les conditions optimales tout le temps.
Cependant, ce qu’on peut faire c’est récupérer un état optimal dès lors qu’une alerte est levée. Lorsqu’une machine s’arrête, si l’architecture est solide, le service restera disponible mais en mode dégradé.
Le mode dégradé c’est toujours mieux que de ne plus avoir de service du tout. Le but, c’est de retrouver un état complètement opérationnel afin d’assurer une bonne expérience pour les utilisateurs.
La bonne nouvelle c’est qu’en industrialisant la mise en production, remettre de nouvelles machines pour remplacer celles qui sont cassées c’est facile et rapide. Cependant il faut avoir l’information que quelque chose va mal pour lancer ces actions.
Voici donc le 3éme aspect de mon travail, garder les meilleures conditions possibles en production, aussi appelé monitoring et supervision. Il s’agit de mettre en place des outils pour recevoir les alertes si quelque chose tourne mal sur notre système.
Mais en y réfléchissant, on peut aller plus loin que juste recevoir une alerte et attendre qu’un technicien intervienne, on peut automatiser la réparation:
- On écarte la machine «malade» (on la garde pour comprendre l’erreur)
- On redémarre une nouvelle machine neuve qui fonctionne
- On relance les vérifications (healthchecks en anglais)
Les vérifications sont l’équivalent des tests unitaires en développement. Ce sont de petits programmes qui peuvent nous assurer que le service est bel et bien en place et en bonne santé.
C’est assez difficile d’automatiser cette partie mais si l’industrialisation s’est bien passée, il n’y a pas de raison pour que la partie MCO ne se passe pas bien.
Sécurité
Quand on en arrive là c’est que notre produit se déploie de manière industrielle et qu’il s’auto-répare en cas de problème.
Mais il reste des aspects dont je n’ai pas parlé. C’est délicat de faire une section à part pour parler de la sécurité car il ne s’agit pas d’un projet que l’on peut ajouter, il n’y a pas de recette miracle pour sécuriser ce qui existe déjà.
La sécurité, on doit l’avoir à l’esprit dans toutes les étapes précédentes. On doit toujours avoir un œil sur cet aspect-là. Du développement à la production, tout doit être fait pour que les données importantes soient protégées, chiffrées et imperméabilisées.
Commençons par le chiffrement. Il s’agit de transformer un message afin que personne ne puisse le lire et votre application sera alors le seul élément à pouvoir le déchiffrer. Ainsi, si un attaquant arrive à intercepter des données, il n’aura pas la capacité de les lire et donc aucun moyens de les exploiter. Si ce sujet vous intéresse, je vous conseille cet article (en anglais) : HTTPS with carrier pigeons
Ensuite, ce qui est important et que peu d’entreprises mettent en place, c’est la procédure d’embauche et la procédure de départ. Lorsqu’un nouveau collègue arrive, comment lui donne-t-on accès à l’ensemble des outils ? Comment fait-on lorsqu’il quitte l’entreprise ?
De nombreuses failles de sécurités découlent de cette partie. Peu d’entreprises sont capables de lister précisément qui a accès aux différents outils qu’elles utilisent et certaines personnes sont donc capable d’agir sur leur environnements productifs sans que l’entreprise n’ait explicitement donnée son accord.
Finalement nous devons maintenir à jours fréquemment les outils que l’on utilise. L’un des avantage de l’industrialisation des mises en production nous permet d’appliquer les mises à jour plus souvent et d’être moins vulnérable.
Cependant le problème de la sécurité en informatique, c’est qu’elle reste très illusoire. On ne pourra jamais être vraiment sûr de sa propre sécurité. On peut seulement diminuer les risques.
La sécurité fait partie de mon travail, au travers de tous les services que je propose.
Survivre aux cataclysmes
Jusque-là, je vous ai parlé de ce qu’on peut mettre en place pour avoir une production qui tient la route. Et c’est ainsi qu’on en arrive au dernier aspect de mon travail, disaster recovery, ou l’art de survivre à l’apocalypse.
Bon, OK, en cas de chute de météorite qui mettrait fin à l’humanité, votre production sera peut-être le cadet de vos soucis. Mais quand une pelleteuse arrache les fibres optiques de votre datacenter, la production ne sera juste plus accessible.
Concrètement, surmonter ce genre d’évènement n’est pas un problème si l’on a correctement industrialisé les mises en production. Cela nous prendra juste du temps pour rétablir les conditions normales de fonctionnement.
Le but ici c’est de rester proactif, prévoir les pires cas imaginables et prendre conscience de la probabilité de ce genre d’événement. Perdre un datacenter, ça n’arrive pas tous les jours mais c’est malheureusement suffisamment fréquent pour que j’en subisse environ 2 par an. Je ne compte pas ceux dont j’entends parler mais qui n’affecte pas les services sur lesquels je travaille.
Il n’y a pas grand chose à faire quand les infrastructures elle-même cassent sous vos pieds, aussi solide que soit votre installation, vous en serez victime.
Mais plutôt que de baisser les bras et prier pour que cela ne se produise pas ou se produise peu, nous pouvons nous y préparer :
- Imaginer les catastrophes potentielles
- Évaluer le risques de chacune
- Évaluer l’impact potentiel sur votre production
- Se préparer à l’impact
Ces événements douloureux sont théoriquement rares mais croyez-moi, ça arrive, et plus souvent qu’on ne le pense. S’y préparer c’est un peu comme suivre une formation aux premiers secours dans le fond, on espère ne jamais avoir à s’en servir mais quand on en a besoin on est heureux d’avoir fait l’effort de suivre ces cours.
Conclusion
Je me suis récemment rendu compte que tout cet univers de compétences était complètement étranger aux personnes que je rencontre. Elles continuent de me demander, même après plusieurs années, « Mais concrètement, c’est quoi ton travail ? ».
C’est cette question récurrente qui m’a décidé à écrire cet article. Je pense avoir fait un rapide tour de mon travail ici, éclairci quelques notions sur lesquelles je travaille.
Comme je le disais au début, expliquer ce que je fais est un petit challenge en soi.
Rencontrer quelqu’un, ne pas connaître ses affinités avec le monde informatique et lui expliquer mon travail est une problématique récurrente.
Chaque point que j’ai évoqué dans cet article pourrait être l’objet d’autres articles, sans compter les notions que je n’ai pas abordés tel que la culture DevOps, les méthodologies que nous mettons en place avec les équipes de développement ou encore les problématiques liées aux réseaux.
J’espère que suite à cet article, vous aurez une meilleure vision de ce que peut être un site internet ou une application mobile.
Je vais écrire d’autres articles dans ce style, pour éclaircir les notions sur les lesquelles nous travaillons tous les jours.
À bientôt,